
Heyo,
It is finally the time to wind up the GSoC work on which I have been buried for the past three months. First of all, let me thank Santhosh, Hrishi and Vasudev for their help and support. I seem to have implemented, or at least proved the concepts that I mentioned in my initial proposal. A spell checker that can handle inflections in root word and generate suggestion in the same inflected form and differentiate between spelling mistakes and intended modifications has been implemented. The major contributions that I made were to
- Improve LibIndic’s Stemmer module. - My contributions
- Improve LibIndic’s Spell checker module - My contributions
- Implement relatively better project structure for the modules I used - My contributions on indicngram
1. Lemmatizer/Stemmer
TLDR
My initial work was on improving the existing stemmer that was available as part of LibIndic. The existing implementation was a rule based one that was capable of handling single levels of inflections. The main problems of this stemmer were
- General incompleteness of rules - Plurals (പശുക്കൾ), Numerals(പതിനാലാം), Verbs (കാണാം) are missing.
- Unable to handle multiple levels of inflections - (പശുക്കളോട്)
- Unnecessarily stemming root words that look like inflected words - (ആപത്ത് -> ആപം following the rule of എറണാകുളത്ത് -> എറണാകുളം)
The above mentioned issues were fixed. The remaining category is verbs which need more detailed analysis.
I too decided to maintain the rule-based approach for lemmatizer (actually, what we are designing is half way between a stemmer and lemmatizer. Since it is more inclined towards a lemmatizer, I am going to call it that.) mainly because for implementing any ML or AI techniques, there should be sufficient training data, without which the efficiency will be very poor. It felt better to gain higher efficiency with available rules than to try out ML techniques with no guarantee (Known devil is better logic).
The basic logic behind the multi-level inflection handling lemmatizer is iterative suffix stripping. At each iteration, a suffix is identified from the word and it is transformed to something else based on predefined rules. When no more suffixes are found that have a match on the rule set, we assume the multiple levels of inflection have been handled.
To handle root words that look like inflected words (hereafter called ‘exceptional words’) from being stemmed unnecessarily, it is obvious we have to use a root word corpus. I used the Datuk dataset that is made available openly by Kailash as the root word corpus. A corpus comparison was performed before the iterative suffix stripping started, so as to handle root words without any inflection. Thus, the word ആപത്ത് will get handled even before the iteration begins. However, what if the input word is an inflected form of an exceptional word, like ആപത്തിലേക്ക്? This makes it necessary to introduce the corpus comparison step after each iteration.

At each iteration, suffix stripping happens from left to right. Initial suffix has 2nd character as the starting point and last character as end point. At each inner iteration, the starting point moves rightwards, thus making the suffix shorter and shorter. Whenever a suffix is obtained that has a transformation rule defined in the rule set, it is replaced with the corresponding transformation. This continues until the suffix becomes null.
Multi-level inflection is handled on the logic that each match in rule set induces a hope that there is one more inflection present. So, before each iteration, a flag is set to False. Whenever a match in ruleset occurs at that iteration, it is set to true. If at the end of an iteration, the flag is true, the loop repeats. Else, we assume all inflections have been handled.
Since this lemmatizer is also used along with a spellchecker, we will need a history of the inflections identified so that the lemmatization process can be reversed. For this purpose, I tagged the rules unambiguously. Each time an inflection is identified, that is the extracted suffix finds a match in the rule set, in addition to the transformation, the associated tag is also pushed to a list. As the result, the stem along with this list of tags is given to the user. This list of tags can be used to reverse the lemmatization process - for which I wrote an inflector function.
A demo screencast of the lemmatizer is given below.
So, comparing with the existing stemmer algorithm in LibIndic, the one I implemented as part of GSoC shows considerable improvement.
Future work
- Add more rules to increase grammatical coverage.
- Add more grammatical details - Handling Samvruthokaram etc.
- Use this to generate sufficient training data that can be used for a self-learning system implementing ML or AI techniques.
2. Spell Checker
TLDR
The second phase of my GSoC work involved making the existing spell checker module better. The problems I could identify in the existing spell checker were
- It could not handle inflections in an intelligent way.
- It used a corpus that needed inflections in them for optimal working.
- It used only levenshtein distance for finding out suggestions.
As part of GSoC, I incorporated the lemmatizer developed in phase one to the spell checker, which could handle the inflection part. Three metrics were used to detect suggestion words - Soundex similarity, Levenshtein Distance and Jaccard Index. The inflector module that was developed along with lemmatizer was used to generate suggestions in the same inflected form as that of original word.
There were some general assumptions and facts which I inferred and collected while working on the spell checker. They are
- Malayalam is a phonetic language, where the word is written just like it is pronounced. This is opposite to the case of English, where alphabets have different pronunciations in different words. Example is the English letter “a” which is pronounced differently in “apple” and “ate”.
- Spelling mistakes in Malayalam, hence, are also phonetic. The mistakes occur by a character with similar pronunciation, usually from the same varga. For example, അദ്ധ്യാപകൻ may be written mistakenly as അദ്യാപകൻ, but not as അച്യാപകൻ.
- A spelling mistake does not mean a word that is not present in the dictionary. The user has to be considered intelligent and he should be trusted not to make mistakes. A word not present in dictionary can be an intentional modification also. A "mistake" is something which is not in the dictionary AND which is very similar to a valid word. If a word is not found in dictionary and no similar words are found, it has to be considered an intentional change the user induced and hence should be deemed correct. This often solves the issues of foreign words deemed as incorrect.
- Spelling mistakes in inflected words usually happen at the lemma of the word, not the suffix. This is also because most commonly used suffix parts are pronounced differently and mistakes have a smaller chance to be present there.
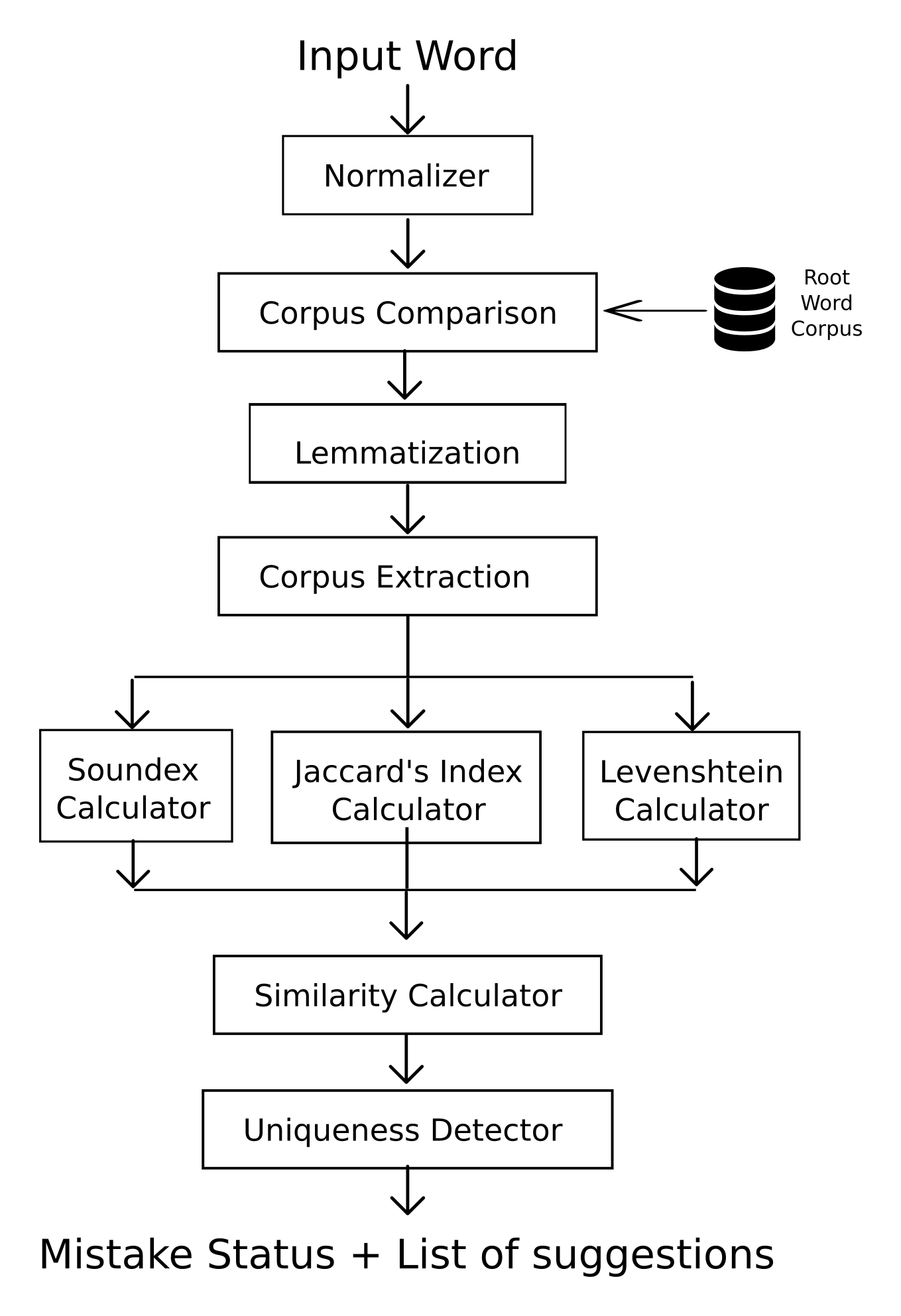
The first phase, obviously is a corpus comparison to check if the input word is actually a valid word or not. If it is not, suggestions are generated. For this, a range of words have to be selected. From the logic of Malayalam having phonetic spelling mistakes, the words starting with the characters that are linguistic successor and predecessor of the first character of the word is selected. That is, for the input words ബാരതം, which have ബ as first character the words selected will be the ones starting by ഫ and ഭ. Out of these words, the top N (which is defaulted to 5) words have to be found out that are most similar to the input word.
Three metrics were used for finding out similarity between two words. For Malayalam, a phonetic language, soundex similarity was assigned the top priority. To handle the words that were similar but not phonetically similar because of a difference on a single character that defines phonetic similarity, levenshtein distance was also used. This finds out distance between two words, or the number of operations needed for one word to be transformed to other. To handle the other words, Jaccard index was also used. The priority was assigned as soundex > levenshtein > jaccard. Weights were assigned to each possible suggestion based on the values of these three metrics based on the following logic:
If soundex == 1, similarity = 100
Elseif levenshtein <= 2, weight = 75 + (1.5 * jaccards)
Elseif levenshtein < 5, weight = 65 + (1.5 * jaccards)
Else, weight = 0
To differentiate between spelling “mistakes” and intended modifications, the logic used that if a word did not have N suggestions that have weight > 50, it is most probably an intended word and not a spelling mistake. So, such words were deemed correct.
A demo screencast of the spell checker is given below.
3. Package structure
The existing modules of libindic had an inconsistent package structure that gave no visibility to the project. Also, the package names were too general and didn’t convey the fact that they were used for Indic languages. So, I suggested and implemented the following suggestions
- Package names (of the ones I used) were changed to libindic-
. Examples would be libindic-stemmer, libindic-ngram and libindic-spellchecker. So, the users will easily understand this package is part of libindic framework, and thus for indic text. - Namespace packages (PEP 421) were used, so that import statments of libindic modules will be of the form
from libindic.<module> import <language>. So, the visibility of the project ‘libindic’ is increased pretty much.